あとN+1回寝るとISUCONです。私はいま予選突破の夢を見つつNew Relicを素振っています。
本記事ではNew Relicの説明は特にしません。また、Rubyで実験しててちょっとハマったところを掘り下げたログが実はメインです。
(2020-07-22追記) 本記事を書いたときには気付いていなかったのですが同じことを公式のWebinarでも行うようでした。(7月30日開催|せっかく無料なのでISUCONでNew Relicをスッと使う方法)RubyだけでなくGo, Pythonの設定の話やその他盛りだくさんなので期待!!
New Relic meets ISUCON
New Relicは業務で過去に使っていて大変便利だったのでISUCONもこれぐらい楽にメトリクス見てぇな〜と思っていたら、自腹契約して使うという道もあったのだということをISUCON9優勝の白金動物園mirakuiさんによる振り返りで学びました。
今回はたまたま別件で間違って Annual Subscription を自腹契約してしまった New Relic の個人ライセンスがあったので、それを使いました。分析できることは自前のスクリプトでやってるときとだいたい同じなんだけど、僕だけじゃなくてメンバーがベンチ結果分析に参加したり、同じ数字を見て語れるところが便利でした
チーム白金動物園として ISUCON 9 予選を通過しました - 昼メシ物語
それはそれで良い話なのですが、なんと2020年のISUCON10ではNew Relic社がスポンサーについており、New Relic全機能を大会前後の期間中制限なく利用できるライセンスを参加者全員に提供するというすごいことになっています。自腹契約しなくても自作スクリプト頑張らなくても分析が始められます。(気に入ったらお勤め先でエンタープライズ契約しよう!)
New Relicアカウント取得
以下に従って進めるだけです。
ただし、過去に登録済のメールアドレスで登録するとメールが永遠に届かないことがある(自分がそうだった、昔いつか登録したのを忘れてた)のでその場合は別メールアドレスやエイリアスを使うなどして回避しましょう。
blog.newrelic.co.jp
isucon9-qualify環境構築
本題ではないのでさらっと。
やり方はなんでも良いのだけど僕は https://github.com/matsuu/vagrant-isucon を使い、Vagrantで環境構築してます。8以前の過去問に比べると言語バージョンとか諸々が比較的新しいのでVirtualBoxを起動しておいて、vagrant upすれば動きました。
$ git clone https://github.com/matsuu/vagrant-isucon
$ cd vagrant-isucon/isucon9-qualifier-standalone
$ vagrant up
sshで仮想マシンに繋いだら、最初はGolangのサービスが起動しているのでRubyに切り替える。
$ vagrant ssh
$ sudo systemctl stop isucari.golang.service
$ sudo systemctl disable isucari.golang.service
$ sudo systemctl start isucari.ruby.service
$ sudo systemctl enable isucari.ruby.service
ベンチマークテストが完走すれば環境構築OK。
$ cd /home/isucon/isucari
$ bin/benchmarker
(ログ省略)
{"pass":true,"score":1410,"campaign":0,"language":"ruby","messages":[]}
New Relicの導入
まずは公式通り進めていきます。ログインするとapplicationの各言語ごとのsetup手順が出てきます。こんな感じのURLです (以下setup pageと呼ぶ)。 https://rpm.newrelic.com/accounts/xxx/applications/setup#ruby
さらにframework別の手順も Sinatra instrumentation | New Relic Documentation などに記されていますので一読すればOK。
Install gem
source 'https://rubygems.org'
+gem 'newrelic_rpm'
gem 'puma'
gem 'sinatra'
...
$ cd /home/isucon/isucari/webapp/ruby
$ /home/isucon/local/ruby/bin/bundle install
applicationからgemを読む
Railsと違って明示的にrequireする必要があります。Sinatra instrumentation | New Relic Documentation によるとSinatraの読み込み直後におく必要があるようです。
require 'json'
require 'securerandom'
require 'sinatra/base'
+require 'newrelic_rpm'
require 'mysql2'
設定ファイルを配置
newrelic.ymlを setup page からダウンロードし、application root (/home/isucon/isucari/webapp/ruby/)に置く。
その他
New Relic関連のlog
デフォルトだと /home/isucon/isucari/webapp/ruby/log/newrelic_agent.log にはログが吐かれます。設定がちゃんとできてるかな?と思ったらログに以下のような記述があるか見てみましょう。
[2020-07-22 11:58:45 +0000 vagrant (32128)] INFO : Reporting to: https://rpm.newrelic.com/accounts/:account_id/applications/:application_id
ライセンスキーの扱い
デフォルトではnewrelic.ymlに記載されているが、secret情報をgit historyに含めてしまうのは好ましくないです。
(git pushしてrepositoryをpublicにすると世界中の人がライセンスを利用できてしまう)
newrelic.ymlからlicense_key: xxxxxの行を消し、プロセス起動時に環境変数として与えるようにしておくと安心です。
NEW_RELIC_LICENSE_KEY=xxxxx
Ruby agent configuration | New Relic Documentation
ここまでは簡単ですね。ここからちょっと悩みました。
benchmarkerが失敗する
上述の手順でセットアップした直後にベンチマーカーを実行するとfailします。
$ bin/benchmarker
(ログ省略)
2020/07/21 08:58:07 main.go:129: cause error!
{"pass":false,"score":0,"campaign":0,"language":"ruby","messages":["POST /login: got response status code 500; expected 401","GET /settings: got response status code 500; expected 200","GET /settings: got response status code 500; expected 200","GET /items/18697.json: got response status code 500; expected 200","POST /login: got response status code 500; expected 200","GET /items/50000.json: got response status code 500; expected 200","GET /upload/336bd3af5fbb247a55354184a3dfb35f.jpg: got response status code 500; expected 200","POST /items/edit: got response status code 500; expected 200 (item_id: 409)"]}
期待するレスポンスが返っていない。アプリケーションの挙動を変えてしまった。
省略したログからスタックトレースを抜粋して貼ったのが以下。
"status code: 500; body: RuntimeError: can't add a new key into hash during iteration
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:31:in `accept'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:46:in `preferred_type'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/show_exceptions.rb:92:in `prefers_plain_text?'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/show_exceptions.rb:26:in `rescue in call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/show_exceptions.rb:21:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/newrelic_rpm-6.12.0.367/lib/new_relic/agent/instrumentation/middleware_tracing.rb:101:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:194:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/newrelic_rpm-6.12.0.367/lib/new_relic/agent/instrumentation/middleware_tracing.rb:101:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:1950:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:1502:in `block in call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:1729:in `synchronize'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:1502:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/newrelic_rpm-6.12.0.367/lib/new_relic/agent/instrumentation/middleware_tracing.rb:101:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/tempfile_reaper.rb:15:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/lint.rb:49:in `_call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/lint.rb:37:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/show_exceptions.rb:23:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/common_logger.rb:33:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/sinatra-2.0.7/lib/sinatra/base.rb:231:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/chunked.rb:54:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/rack-2.0.7/lib/rack/content_length.rb:15:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/puma-4.1.0/lib/puma/configuration.rb:228:in `call'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/puma-4.1.0/lib/puma/server.rb:664:in `handle_request'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/puma-4.1.0/lib/puma/server.rb:467:in `process_client'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/puma-4.1.0/lib/puma/server.rb:328:in `block in run'
/home/isucon/isucari/webapp/ruby/.bundle/ruby/2.6.0/gems/puma-4.1.0/lib/puma/thread_pool.rb:135:in `block in spawn_thread'"
RuntimeError: can't add a new key into hash during iteration
名前の通り、Hashをイテレーションで処理している破壊的な変更として新しいkeyを挿入しようとすると起きるRuntimeErrorとのこと。わかりやすいエラーメッセージだ!!
で、Sinatraの該当バージョンの該当コードを見るのですがイテレーションなんてしてないんですよねぇ…。
ググってみたところマルチスレッド環境下だと、別スレッドでイテレーションしてる最中に上記の破壊的なコードが実行されたりすると起きる雰囲気がある。
can't add a new key into hash during iterationが謎の状況で発生しているように見えるときは - 猫型の蓄音機は 1 分間に 45 回にゃあと鳴く
エラーが起きるエンドポイントに単発でリクエストを送ってもRuntimeErrorが再現しないのと、そもそもログを見ると色んなエンドポイントで起きているので単一のエンドポイントの問題でなくRack middlewareとかそのへんの問題な気がしてくる。
マルチスレッドの問題なら非マルチスレッドのWeb server試すか〜と思って起動コマンドを変更してみます。
systemctlに登録してるserviceのコマンドを書き換えてWEBrickにしてみる。知らなかったけど、rackup -sオプションで何も指定しないとrack gem内の実装で書かれている優先度順に試行されるのだった(puma > falcon > webrick)。
[Unit]
Description = isucon9 qualifier main application in ruby
[Service]
WorkingDirectory=/home/isucon/isucari/webapp/ruby
EnvironmentFile=/home/isucon/env.sh
-ExecStart = /home/isucon/local/ruby/bin/bundle exec rackup -p 8000
+ExecStart = /home/isucon/local/ruby/bin/bundle exec rackup -s WEBrick -p 8000
コマンドいじったのでdaemon-reloadしてからrestart、からのベンチマーカ実行すると…
$ sudo systemctl daemon-reload
$ sudo systemctl restart isucari.ruby.service
$ bin/benchmarker
{"pass":true,"score":1410,"campaign":0,"language":"go","messages":[]}
pass!!
ヨッシャ、New Relicのwebで各種メトリクスや統計が見られるようになった!!
 顧客が本当に欲しかったもの
顧客が本当に欲しかったもの
余談: 初期化処理の#POST initializeまで記録されてて邪魔なので newrelic_ignore '/initialize' を書いておくと見やすくなるかも。
余談2: New Relicの力をフルに使うとTransaction traceなどの機能でクエリの内容やかかった時間が見られるようになりますが、 ISUCON9予選のRuby実装そのままではDatabaseへのクエリでかかっている時間は解析できません。クエリを実行するのにActiveRecordなどではなくMysql2::Clientを直接使っているためです。(New Relic agentがフックを仕込んでいない)
(追記2020-07-30) New RelicのセミナーでMySQL2::Clientを拡張してクエリを計測する方法の説明がありました。コードはこれ。
とはいえpuma使えないって…そんなことあるか…?
ちなみにwebrickに切り替えたらベンチマークの結果も早速下がってます。
bundle exec rackup -> bundle exec puma
mtsmfmさんから「本当にマルチスレッドの問題なのか、threads数変えて試してみては?」との本質的な指摘をもらったので試してみる。
pumaのconfig file書くよりコマンドを書き換えたほうが早いのでまたisucari.ruby.serviceをいじる。
そういえばpumaコマンドじゃなくてrackupだったな…まずはpumaコマンドでちゃんと動くか見てみるか〜という感じでthreads数を変えずにコマンドだけ変更。
-ExecStart = /home/isucon/local/ruby/bin/bundle exec rackup -s WEBrick -p 8000
+ExecStart = /home/isucon/local/ruby/bin/bundle exec puma -b tcp://0.0.0.0:8000
で、これで再起動したあとにベンチマーカーを試しに実行すると…なんとpassしました。
ええ… rackupとpumaコマンド変えただけでSinatraの内部でRuntimeError起きるようになる、そんなことあるか…?
rackupとpumaの違い
挙動が違うからにはまぁ、何か違うのだろうということでrack/rack中心にコードリーディングしていく。
server (Puma::Serverインスタンス) をrunするところ… wrapped_appってなんや、何で包んどるんや。
server.run(wrapped_app, **options, &block)
その正体はこちら。appのmiddleware包み。
def build_app(app)
middleware[options[:environment]].reverse_each do |middleware|
middleware = middleware.call(self) if middleware.respond_to?(:call)
next unless middleware
klass, *args = middleware
app = klass.new(app, *args)
end
app
end
def wrapped_app
@wrapped_app ||= build_app app
end
結局素材はなんなのか、がわかるのがこちら。
def default_middleware_by_environment
m = Hash.new {|h, k| h[k] = []}
m["deployment"] = [
[Rack::ContentLength],
logging_middleware,
[Rack::TempfileReaper]
]
m["development"] = [
[Rack::ContentLength],
logging_middleware,
[Rack::ShowExceptions],
[Rack::Lint],
[Rack::TempfileReaper]
]
m
end
def middleware
default_middleware_by_environment
end
あ〜ここで完全に一部を理解しました(?)。
RACK_ENVもしくはrackup -E optionの値がdeploymentかdevelopmentの場合 (デフォルトはdevelopment)、rackupコマンドで起動されるappにはいくつかのRack middlewareが足された状態になる、と。
上述のスタックトレースをよく見ると確かにこのmiddlewareを介して呼ばれてます。
rackup -E foo
じゃあこのmiddlewareが足されない状態なら大丈夫なのでは?ということで環境をfooにしてrackupします。deploymentとdevelopment以外ならなんでも良いはず。
-ExecStart = /home/isucon/local/ruby/bin/bundle exec puma -b tcp://0.0.0.0:8000
+ExecStart = /home/isucon/local/ruby/bin/bundle exec rackup -E foo -p 8000
これで再起動したあとにベンチマーカーを試しに実行すると…予想通りpassしました。
ウォーッ、rackupがdevelopment環境で足してくるRack middlewaresと、マルチスレッドと、newrelic_rpmの組み合わせで再現する問題だということがわかった!!
わかったところで力尽きたのでこれをNew Relic forumかnewrelic_rpmにレポートして手を引きます。
余談: app_nameは環境に応じて変わる
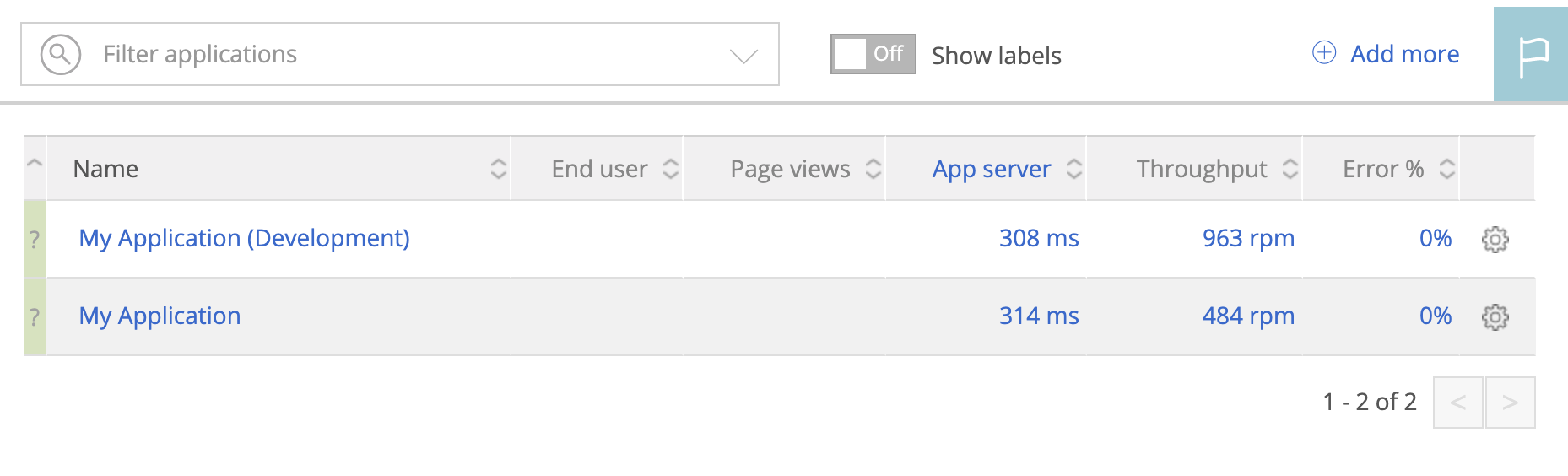
newrelic.ymlの設定次第では環境 (= RACK_ENVまたは-E optionで指定する値) によってapp_nameが変わります。特定のapp_nameのpageだけをウォッチしていて「あれ〜データ来ないな〜」とならないよう注意。
デフォルトの設定だとこんな感じでした。
My Application (Development) => -E optionなし = デフォルトのdevelopmentMy Application => development, staging 以外
2つのアプリケーションが一覧に出ているので見たいほうを見ましょう。
 gyazo.com
gyazo.com
まとめ
- New Relicは便利
- ISUCON9の過去問の構成のとき、Rubyの実装にNew Relicの設定を入れるだけだとベンチマークテストが失敗する
- 以下のいずれかで、特定のRack middlewareと
newrelic_rpmの組み合わせを回避すれば成功する
- WEBrickを使う (
bundle exec rackup -s WEBrick)
environmentをdevelopment以外にする (bundle exec rackup -E production etc.)- pumaコマンドで起動する (
bundle exec puma)
まぁ、本番だったら時間も限られているのでこんな風にコードリーディングなんてせずに見つかったワークアラウンドのどれかで回避しているだろうとは思いますが、本番で予期しないことが起きると焦って一日が一瞬で終わるので利用したいツールの素振りを予めしておくのは大事ですね。
また、New Relicは特に設定せずとも突っ込むだけでアプリケーションのモニタリングがめちゃ捗りますが、デフォルトのアプリケーション実装だとスロークエリ分析までは届かなかったり、システム全体のボトルネック特定は難しいかもしれません(特定エンドポイントの外部APIリクエストが重い、とかはわかる)。topコマンドやMySQL slow query logなど古馴染みのツールとうまく併用して最大限役立てたいところです。







